Zielony tygrys bez sierści
Testy kart NVIDIA GeForce GTX 480 i GTX 470 (Fermi)
 136226
136226 5
5 Premiera Fermi miała miejsce ponad miesiąc temu, jednak dla polskiego rynku Nvidia przeznaczyła mniej tych kart, niż Rzymian przeżyło po wojnie z Galami – konkretnie dwie. Na pewno pamiętacie dziesiątki, jak nie setki newsów w których pokazywaliśmy Wam domniemany wygląd, osiągi i inne plotki związane z kartami GTX 470 i GTX 480. Wszystko to sprawiło, że produkty te są najbardziej oczekiwanymi kartami graficznymi chyba w historii. W dzisiejszej recenzji sprawdzimy jak nowe modele wypadają w stosunku do konkurencyjnych Radeonów HD 5850 i HD 5870 oraz na jakim poziomie jest ich pobór mocy, kultura pracy, a także stosunek cena/jakość. Mam nadzieję, że po tej lekturze każdy gracz będzie miał jasny obraz na obecny rynek akceleratorów grafiki. Zapraszam do artykułu!
Premiera Fermi miała miejsce ponad miesiąc temu, jednak dla polskiego rynku Nvidia przeznaczyła mniej tych kart, niż Rzymian przeżyło po wojnie z Galami – konkretnie dwie. Na pewno pamiętacie dziesiątki, jak nie setki newsów w których pokazywaliśmy Wam domniemany wygląd, osiągi i inne plotki związane z kartami GTX 470 i GTX 480. Wszystko to sprawiło, że produkty te są najbardziej oczekiwanymi kartami graficznymi chyba w historii. W dzisiejszej recenzji sprawdzimy jak nowe modele wypadają w stosunku do konkurencyjnych Radeonów HD 5850 i HD 5870 oraz na jakim poziomie jest ich pobór mocy, kultura pracy, a także stosunek cena/jakość. Mam nadzieję, że po tej lekturze każdy gracz będzie miał jasny obraz na obecny rynek akceleratorów grafiki. Zapraszam do artykułu! Spis treści

Różnic w stosunku do poprzednich konstrukcji nie ma wcale tak dużo jak oczekiwaliśmy. Wszystko zostało podporządkowane zgodności z DirectX 11. Nowy układ zbudowany został z 3 miliardów tranzystorów.

Główną częścią rdzenia są bloki procesorów SM, w liczbie 16 sztuk, podzielone na cztery oddzielne klastry. Liczba równoległych rdzeni wynosi 512, natomiast dla przykładu w konkurencyjnej serii HD 5000 jest ich 320. Kolejnym usprawnieniem jest nowy silnik GigaThead, który ma za zadanie rozdzielanie wątków, wprowadzenie szybkiej pamięci L2 cache oraz rezygnacja z jednostek Texture Processing Clusters. Warto też wspomnieć o nowych, przebudowanych blokach ROP, których sześć sztuk posiada po osiem jednostek renderujących.

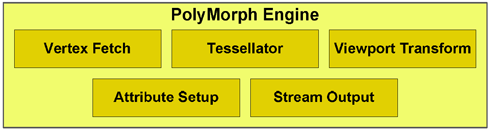
W serii GF100 rdzenie CUDA podzielone są na cztery procesory po 128 sztuk. Poniżej macie schemat rasteryzatorów, które pozwalają na wydajniejsze przekształcenia geometryczne, a co za tym idzie lepszy podział wielokątów (teselacje). Bloki SM posiadają podporządkowaną jednostkę polimorficzną, która ma za zadanie dokonywać przemian geometrycznych. Przekłada się to aż na 8x szybsze zabiegi nowych układów na elementach geometrycznych. Takie obliczenia pozwalają nam wiązać z Fermi duże nadzieje.
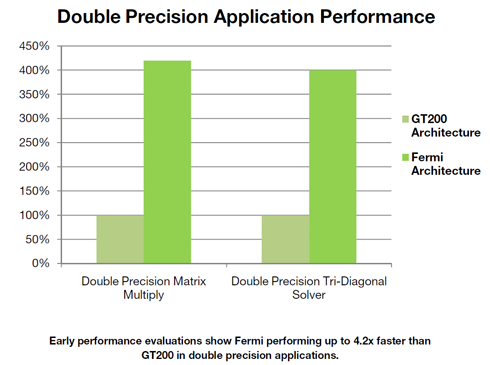
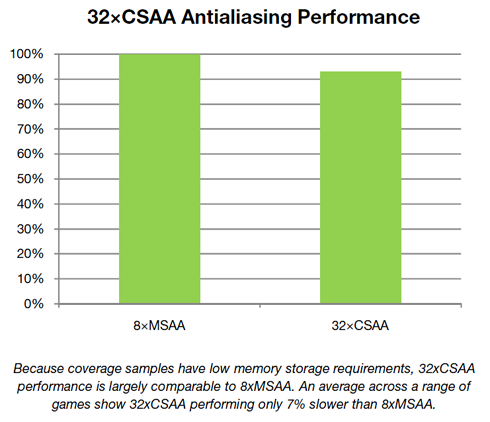
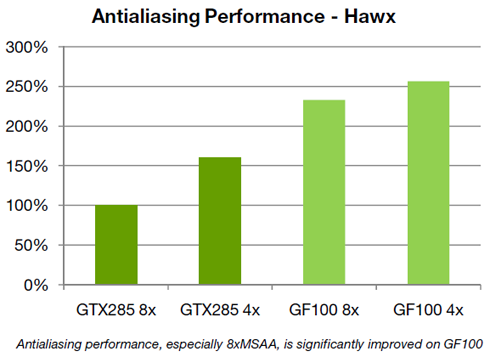
Poniższy wykres prezentuje wydajność teksturowania w stosunku do układów GF200. Nowszy układ nie posiada już niezależnych klastrów TPC. Mniejsza liczba jednostek adresujących tekstury, które pracują jednak z większą efektywnością gwarantuje nam szybszą komunikację.
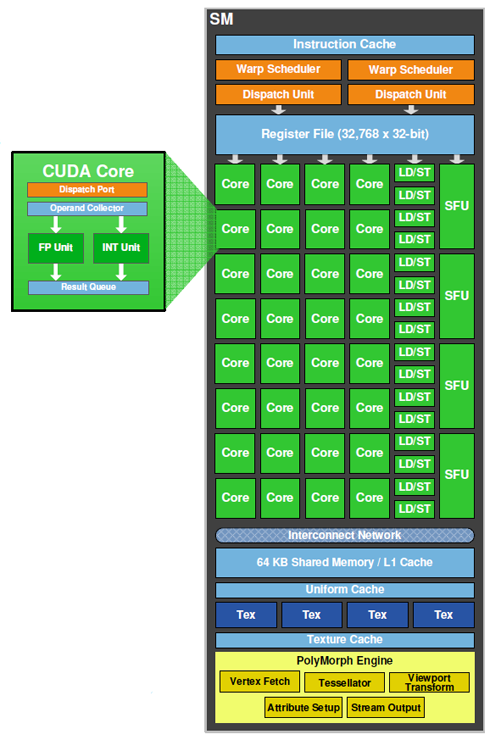
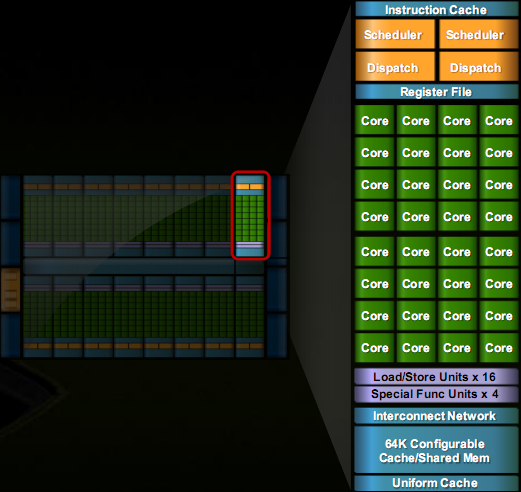
Kolejną znaczącą zmianą jest budowa jednostek obliczeniowych w bloku SM, które zbudowane zostały z dwóch części: zmienno- i stałoprzecinkowej. Mają dzięki temu możliwość jednoczesnego wykonywania działania sumy i iloczynu, a zarazem braku utraty dokładności. Każdy pojedynczy blok SM posiada 16 jednostek ładowania i przechowywania, które pozwalają na adresację nawet 16 wątków podczas jednego cyklu zegarowego. Kolejnym elementem SM są 4 jednostki SFU, które zajmują się podczas obliczeń funkcjami sinus, cosinus czy działaniem pierwiastkowania.

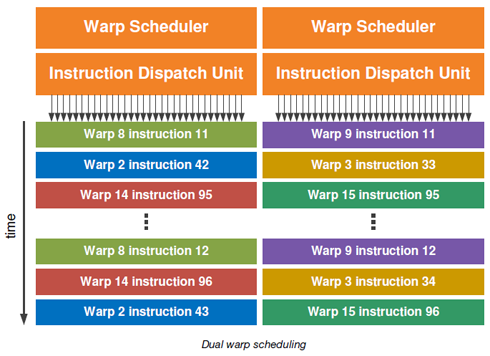
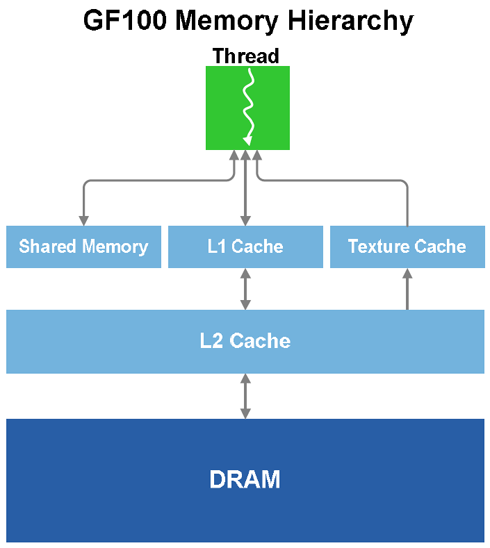
Wprowadzenie operacji atomowych zapewnia nam ciągły przepływ wątków, bez możliwości wzajemnego blokowania. Kontroler pamięci GDDR5 posiada system korekcji EDC oraz obsługę Error Correction Code.
Instrukcje w architekturze Parallel Thread eXEcution, która jest tutaj innowacją pozwala na pracę całego układu, jako procesora wątkowego. Są one tłumaczone przez specjalny sterownik, tak żeby mogły być realizowane przez warstwę sprzętową. Pozwala to osiągnąć bardzo wysoką wydajność karty w najróżniejszych obliczeniach. Nie sposób zapomnieć o chyba najważniejszej różnicy jaką wprowadza 40-bitowa przestrzeń adresowa, czyli obsłudze interpretatora C++. Możemy wykonywać krótkie części kodu, bez zbędnych rozgałęzień.

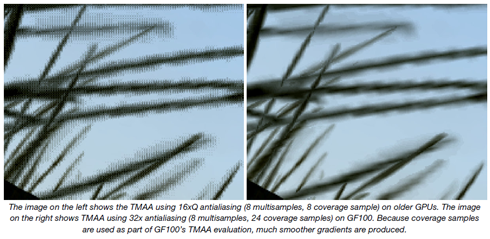
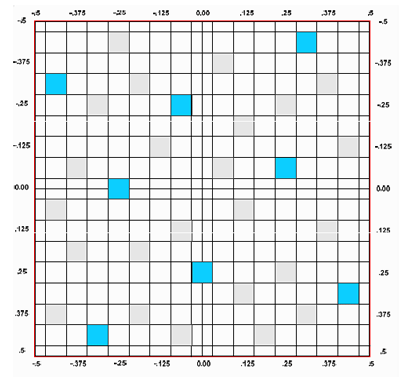
Najlepszym przykładem działania tej technologii jest wygładzenie krawędzi na poniższym obrazku, gdzie mamy scenę z liśćmi i porównanie do MSAA. W środowisku DirectX9 będziemy mogli wykorzystać przeźroczystość, na co pozwalają 24 dodatkowe próbki ATC.
Warto przeczytać:
Do góry
 0
0
Komentarze
2010-04-30 20:13:53
2010-05-01 09:45:29
Catalyst 8.11 - ASUS HD 4870 X2
Catalyst 9.10 - Radeon HD 5850 i 5870
Catalyst 9.12 - Radeon HD 5970.
I robi taki test osoba, która pracuje w tym temacie długi czas, a nie wie, że przy tak głośnych premierach kart, ważnych kart, porównaniach, nie dokonuje testów przy jednakowych warunkach. Nie mówię, aby powtarzać wszystkie testy od nowa, ale można było chociaż konkurencyjne układy dla NV, jak HD 5870 i HD 5970 przetestować jeszcze raz na Catalystach 10.3. Swoją drogą, ciekawe czemu autor testował na tak starych driverach karty w Metro 2033 czy w Dircie2? Pewnie chciał, aby Fermi miało lepsze wyniki. Kpina.
Na koniec, przyznajecie nagrody kartom, zaś w tekście piszecie, że Fermi was zawiodło. Narzekacie, ze ceny są za wysokie. Czy w ogóle ktoś czytał ten tekst przed jego publikacją, chyba nie?
Dlaczego wasze testy mają tak wiele błędów, przez co są nierzetelne?
@morticore
Chyba czytaliśmy zupełnie inny artykuł, bo ja tu nie widzę, aby Fermi w DX11 nie miało sobie równych. Wręcz przeciwnie, wypadają tak samo, jak konkurencyjne Radeony.
Pozdrawiam,
2010-05-01 10:53:27
@KamilM, dzięki za konstruktywną krytykę. Trudno się z Tobą nie zgodzić, rzeczywiście bardziej trafne byłoby ograniczenie porównania do kilku Radeonów z serii 5000, bo w końcu z nimi mają rywalizować nowości od NV. W tej kwestii obiecuję poprawę. Również pozdrawiam.
2010-05-01 20:03:48
2010-05-04 14:10:23